


Let’s have a brief look at Windows Failover, HyperV and Site Aware clusters and their failover process. A bit of what should be taken into the account and some of the best practices.
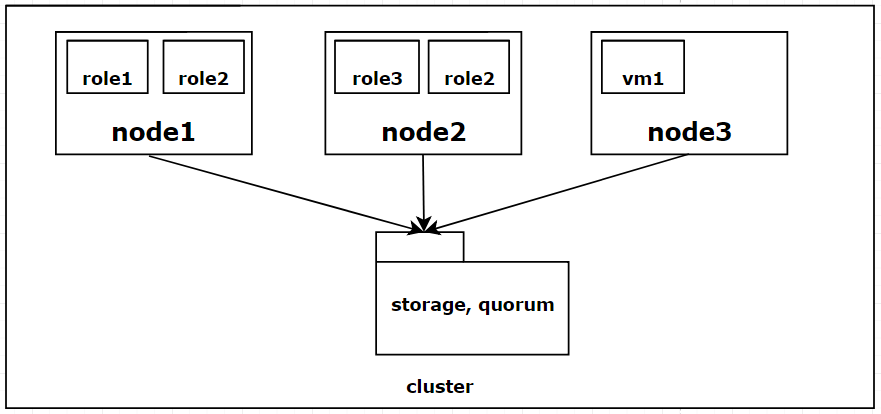
Operating principle
The cluster itself works from server nodes - hosts, that run services and VMs. These services are called roles and they work by utilizing host physical resources (CPU power and memory). The idea of failover cluster is that these services fail-over to another cluster host in the case of a failure, providing high availability.
Storage can be obtained in multiple ways. By using storage array in conjunction with FC or iSCSI, or by using local storage with Storage Spaces Direct for example, but be aware that starting with Windows Server 2016 build 1709 S2D is no longer available so 3rd party software-defined-storage solutions like Starwind should be considered. In this article an external disk array will be used.
From the disk array same Volume/LUN is exported to all of the cluster servers. From which Cluster Shared Volume and quorum is made. In this case interface does not matter that much, but take note that the MPIO should be installed on each host if multiple storage paths are present. If VMs are managed with Failover Cluster Manager, for the sake of simplicity, the default path, from the HyperV manager, can be set to the CSV so that when VMs are being made, the path should always point to the Cluster Shared Volume.

Quorum and Witness
Another essential cluster component is Quorum Witness. In deployments where no more than 5 nodes are present, Quorum should be considered as obligatory requirement to ensure greater cluster continuance. In earlier versions Cluster existence was determined by a simple vote system where every cluster node gets a vote if it’s online. Cluster goes offline when more than 50% of votes are not reached called vote majority. Quorum becomes vital when even number of nodes are running in the cluster. For example, in 2 node scenario - if 1 node fails, the cluster goes down because more than 50% of votes are not met, just the 50%. Same applies to 4 node clusters, without quorum it can tolerate only 1 node failure since 2 nodes does not provide vote majority.
To address this issue Quorum witness was introduced, it can be used as a File share, cluster disk or a new feature in Failover Cluster 2016 called Cloud Witness. It serves as an additional vote to reach majority of votes. With this feature an even number of cluster nodes can tolerate up to half of the cluster being down.

Dynamic Quorum
A feature that dynamically adjusts Quorum and Node votes in order to ensure cluster being online as long as possible. For example, in 3 node scenarios, when one node goes offline its vote is no longer counted, therefore now cluster to exist needs only 1 vote plus quorum (like in 2 node cluster), when the failed node comes back online, cluster continues to operate as usual with all votes being counted. Cluster goes offline when there are no free resources available for services to failover on. More on this scenarios and deployment can be found here.
Failover process, policies
Let’s have a look at the failover process when failures occur. In the event of a sudden power loss to a node, cluster migrates all the failed nodes services and VMs to the other nodes and restarts them there. Node is now marked as Down.

When the host is shut down gracefully, to do the maintenance for example, host informs cluster and all the services are live-migrated to the other nodes, essentially services are not affected.
It gets a bit tricky when it comes to a lost network connection. By default (4-minute time period), services are not migrated when the loss of network link occurs. Instead resources stay on the nodes. The need for such functionality is simple – nowadays small errors may occur far more often than hard failures. Migrating services every time when a small error occurs can be more painful (for the network, application time to restart for example) than by trying to fix the error on the site. If the error cannot be solved in the mentioned 4-minute period, services finally migrate to other nodes. Once again this depends on infrastructure needs and timeout can be adjusted (can be granulated even for separate services and VMs). When node loses its network, it goes into Isolated state, VMs into Unmonitored.

![]()
To continue, if there’s a host in the infrastructure that keeps failing (for some hardware issue for example), by the default policy (3 times per hour) the cluster will put the host into a Quarantine. No services will be migrated back till issues with that host won’t occur for next 2 hours (by default) or it will not be taken out of the quarantine manually. The purpose behind this is so services would not run on failing hosts.

App level failover
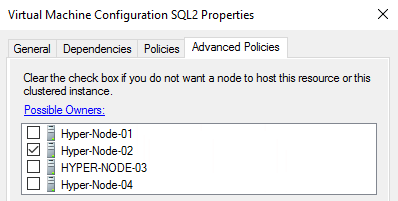
In scenarios when redundancy is achieved in application level which are hosted on cluster VMs, VM failover is no longer needed, since all the migration and role switch is happening on the upper app layer. In host failure event we don’t want all the VMs to be migrated to other hosts or host making it a single-point-of-failure design. In such cases VMs can be created and managed only in HyperV manager without adding it to cluster. But it has its drawbacks like multiple management interfaces, that can make things confusing especially when you have to work with tons of VMs. Another fix for that could be disabling migration altogether but then again it kind of beats the purpose of the HyperV Cluster. A great solution to address this is selecting only one possible owner from Failover Cluster manager VM properties. In this way it is possible to select nodes where VM can be ran on. Once again, the selected VM failover won’t happen as it is configured in the app layer. As image shows multiple nodes can be selected as well.
Site Aware clusters
Another great Server 2016 Failover cluster addition is site aware clusters. It allows to sort hosts by racks, blade chassis and sites. Therefore, services in case of a failure now can be migrated within the rack before migrating to another site which can add some strain to the network. When configuring and then deleting the site aware topology it is good to know that all the child items must be cleared from parents first by specifying flag - parent “”, else you might face some errors.
Another thing worth mentioning is that with the use of Primary site, the option Preferred owners no longer works, all services continue to migrate to the primary site.
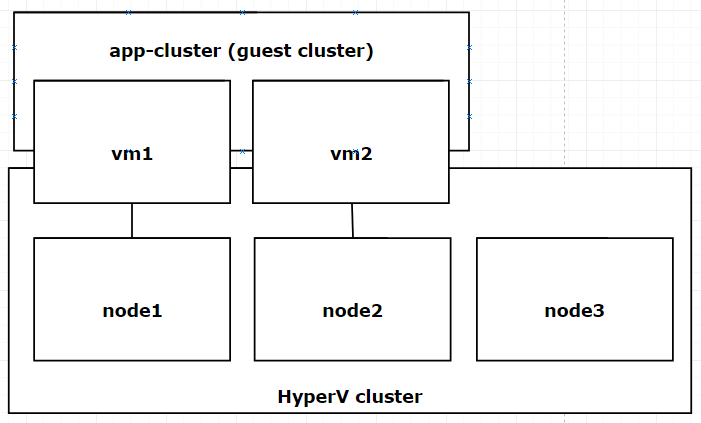
Guest Cluster
In order to achieve HA for apps like SQL or Sharepoint its requirement is to be in a failover cluster. In order keep things simple and avoid the mess of mixing HyperV cluster with other service clusters Guest cluster is used. It is a separate, upper layer cluster running on VMs that are on the HyperV Cluster. Here’s an image for better understanding.
With these new and refined old updates in Failover Cluster 2016, Windows provides high availability greater than ever. All variables can be adjusted to meet the needed requirements so hop on in and try these features as well. All the set-up is pretty painless as long all the updates are installed and with a bit of tinkering it can be run and tested on almost every virtualization supported machine.